爬虫与反爬
什么是爬虫?
爬虫可以理解成一个自动化获取网络内容的程序。如果我想知道豆瓣所有电影的评分,或者携程所有酒店的价格,我当然不会去手工一个一个浏览然后记录下来。我们的做法通常是通过程序来模拟浏览器的点击和访问,然后解析网页里面的内容,自动保存下来。
我们用到的搜索引擎就是建立在爬虫之上的。百度的爬虫每天不间断地爬取整个互联网所有的内容,然后整理保存到数据库,这样我们就可以通过关键字来搜索到全网相关的内容。这类搜索引擎爬虫会遵守网站的爬取协议(robots.txt),把站点允许爬取的内容变得可以在搜索引擎内搜索到。站长们不仅欢迎这种爬虫,而且会通过各种方法(SEO)来提高站点内容在搜索引擎中的排名。
为什么要反爬虫?
遵守协议的搜索引擎爬虫带给网站的收益要远大于与此同时带来的流量负担,而不遵守协议的恶意爬取,可以说是有百害而无一利:
1 增加服务器负载
爬虫程序发起请求的速度过快、并发请求量大,服务器硬件资源和带宽资源都被爬虫占用,严重情况下可能会影响正常用户的访问,导致用户流失和资金损耗。
2 核心内容被爬
像豆瓣、知乎这种以内容为核心的网站,如果文章、回答等被大量爬取,影响相同内容在搜索引擎中的排名,用户被分流;而且绝大部分网站并不注明转载来源,导致文章作者们不再信赖平台,核心用户们流失对平台的影响是毁灭性的。
电商、OTA、O2O平台上的商品价格是这些平台的竞争热点,各大厂商都会爬取竞争对手的价格信息,来给自己的商品一个更有新引力的定价。羊毛党们也会通过对比各平台的价格、优惠活动来选择购买对象。
3 无效数据
由于爬虫的存在,平台的访问数据里大部分是不可信的,这给数据分析团队带来了十分大的困难,无法准确分析用户的浏览习惯。
投放的页面广告也可能被爬虫虚假点击,造成大量的经济损失。
4 网络安全
一些爬虫会被用来访问网站的登录和注册接口,来暴力枚举哪些账号在这个平台有过注册(扫号)或者是利用其他平台泄露的用户账号信息来尝试登录(撞库)。
自动化的渗透工具也会利用爬虫来找到网站存在的系统漏洞,获得网站乃至服务器的权限。
如何反爬虫?
1 HTTP Header
HTTP协议头部中有很多字段,用来标识请求的各种属性。其中的User-Agent字段表示用户所使用的浏览器的各种信息,比如:操作系统、浏览器型号和版本等等,一般爬虫程序使用的请求库都有自己默认的User-Agent值,比如:Python urllib,Java的Commons-HttpClient等等,我们可以通过这个特征来直接禁止带有这些User-Agent的请求。
Cookie:会话标识。HTTP协议通过这个字段来保存用户与服务器的会话内容,如果HTTP头部中没有这个或者其他一些关键字段,那么这次请求也是非法请求。
搜索引擎通常也会有一个特定的User-Agent值,来告知服务器,这次请求来自于搜索引擎。目前,仅有Google、百度、必应、搜狗、雅虎、Yandex提供了DNS反查的方法来确定IP是属于其公司的爬虫,360搜索提供了一个爬虫IP页面但是经测试,已经很久不更新了。所以,对于伪造成搜索引擎User-Agent的爬虫,不能直接通过检查头部字段的方法来判断。
2 频率
爬虫通常需要以较快的速度来请求网站,高效率地获取内容。所以我们可以通过IP和Cookie出现的频率来对访问作限制。
在公共场合,存在许多用户共同使用一个出口IP的情况,比如:机场、酒店、公司、城域网出口等,这个时候如果只针对IP进行频率限制,可能会误杀非常多的正常用户,影响其他用户体验。所以对于公共的IP,每个用户独立的Cookie就可以作为第二层的频率限制指标。
对于搜索引擎爬虫,我们可以在robots.txt里设置爬虫爬取频率的约定:
|
|
通过加入上面的内容在robots.txt中,百度爬虫最低的爬取间隔就被设为了2秒。robots.txt更详细的语法见:http://www.robotstxt.org/robotstxt.html
另外,长时间内,访问频率十分固定的用户可能也是非法爬虫,因为正常人类的浏览有选择偏好,不会所有页面都停留同样的时间。
3 聚合关联
为了规避上面的频率的规则,一般爬虫的解决措施都是通过IP代理池、合法User-Agent池、不同账户Cookie池来应对单个维度的频率限制。所以通过聚合关联:一段时间内一个IP对应的User-Agent数和Cookie数(这条规则在IP为公共出口的情况下请勿使用)。
4 Honeypot 蜜罐
正规搜索引擎第一次访问一个网站时,会先尝试访问网站的robots.txt和sitemap.xml文件来检查网站是否设置了爬取规定,如果一个带有搜索引擎User-Agent的爬虫没有去访问这两个文件,说明这是一个伪造的爬虫。
对于全站爬取的爬虫,程序会自动解析页面中所有的链接,然后对这些链接进行访问。我们可以在robots.txt在设置一个禁止爬虫访问的页面:
|
|
并通过css的display: none属性来对真实用户隐藏,一个真实用户是根本看不到这个链接的,自然也就不可能点击,所以如果有请求来访问这个页面,很有可能这就是一个来自爬虫的请求。
这样的方法通过前端实现的方法还有很多,比如设置颜色透明或者用其他元素挡住这个链接等等。
而对于垂直爬虫(只固定爬取某一动态页面的爬虫),比如某页面通过一动态参数来显示不同内容:http://www.target.com?id=1,更改id会显示不同内容。我们可以设置一个“虚假id”,例如:9999。数据库中根本没有这个id为9999的内容,正常用户是不会访问,而通过枚举来发起请求的爬虫,有很大可能会去访问这个id。
对于使用一些无界面浏览器的爬虫,可以设置一些隐藏的click函数,爬虫通常会去触发所有的可能带有Ajax功能的链接标签。
5 验证码
对于上面提到有异常的公共IP和无法识别的伪造搜索引擎爬虫,最方便最有效的办法就是加验证码。在牺牲一点用户体验的情况下,提高网站内容的安全性。
验证码有很多种:普通的图片验证码、基于知识的验证码(12306)、基于历史的验证码(淘宝购买历史)、基于生物特征的验证码(阿里noCaptcha、极验)。
6 加密
页面的内容可以通过JS函数,异步展示给用户。正常使用浏览器的用户并不会有感知,而使用脚本的爬虫无法运行JS函数,所以不能获取到内容。
更安全地可以使用JS加密库,先生成一个动态token,通过这个token去解密网站的内容。
不过这些方法,都可以通过一些无界面浏览器来模拟正常浏览器的环境来运行JS代码,或者是通过按键精灵等软件模拟真实用户的鼠标点击和浏览来绕过这种前端的风控策略。
猫眼电影采用的反爬策略是,票房和电影票价格采用编码加密。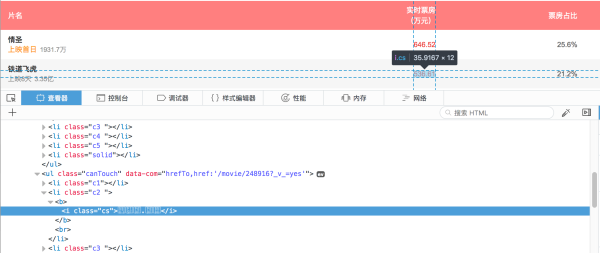
在上图红框中,票房数据是加密unicode编码,通过自定义的字体文件来在页面上可以正常显示。
7 机器学习
列夫·托尔斯泰说过:“幸福的家庭都是相似的,不幸的家庭各有各的不幸。“
对于同一个站点,核心内容的路径都类似,爬虫们的请求基本锁定在几个接口上。是否请求页面的静态资源、是否有连贯的访问逻辑(比如:页面A的链接只出现在了页面B上,如果没有访问B而直接访问了A是明显异常的)、前端鼠标的移动轨迹等等都可以作为一个正常用户的指标。
最后
上面说的所有反爬策略都可以被精心地绕过,在反欺诈领域,我们能做到的只能是无限地提高恶意用户作案的成本。
反欺诈事业任重而道远。